Domina los Costos en la Nube: Optimización de GCS y BigQuery en Google Cloud

Julián Felipe Parra
Technical Specialist

Introducción
En muchas ocasiones, los costos en la nube pueden dispararse debido a una configuración inadecuada o a la falta de conocimiento sobre cómo aprovechar al máximo los servicios disponibles. En el caso de Google Cloud Platform (GCP), los servicios más utilizados para almacenamiento son Google Cloud Storage (GCS) y BigQuery. Sin embargo, sin un enfoque adecuado en su configuración y administración, pueden generar gastos innecesarios.
El objetivo de este artículo es proporcionar un conjunto de recomendaciones para optimizar el uso de estos servicios, enfocándonos en cómo configurar correctamente los buckets de GCS y las tablas de BigQuery, asegurándonos de que cada servicio esté alineado con las necesidades específicas de nuestra implementación. A lo largo del artículo, exploraremos las mejores estrategias para gestionar el ciclo de vida de los datos, decidir cuándo activar el versionado, cómo organizar la estructura de almacenamiento en función del uso o tipología de los datos y qué aspectos técnicos deben considerarse para mantener un control eficiente de los costos.
Además, vamos a abordar un conjunto de preguntas clave que debemos plantearnos al configurar estos servicios. Responder estas preguntas nos ayudará a tomar decisiones más informadas y evitar sobrecostos innecesarios.
También veremos cómo, utilizando las APIs de Google, podremos revisar los metadatos actuales de nuestros recursos, permitiéndonos auditar y mejorar la configuración de nuestros entornos de almacenamiento de forma sencilla y efectiva.
Recomendaciones
Clase de almacenamiento GCS
Utiliza clases de almacenamiento como Standard, Nearline, Coldline, y Archive según la frecuencia de acceso a los datos. Por ejemplo, si los datos no serán accedidos en los próximos 30 días, podrías moverlos a Nearline o Coldline para optimizar los costos.
Ciclo de vida de los objetos en GCS
Configura políticas de ciclo de vida para mover, eliminar o archivar objetos automáticamente basándote en la antiguedad de los mismos. Esto ayuda a reducir el costo de almacenamiento sin intervención manual.
Versionado en GCS
Habilita el versionado solo cuando sea necesario. Si los datos cambian frecuentemente o si necesitas poder recuperar versiones anteriores de un archivo, el versionado es útil. Sin embargo, asegúrate de gestionar las versiones antiguas para no generar costos innecesarios por almacenamiento duplicado.
Buenas prácticas BigQuery
Particionamiento
El particionamiento es una técnica que divide las tablas en segmentos más pequeños y manejables según una columna específica, como la fecha. En BigQuery, el particionamiento por fecha es común, ya que permite reducir la cantidad de datos escaneados durante las consultas. Al particionar las tablas, se optimizan las consultas al enfocarse solo en los segmentos de datos relevantes, lo que mejora el rendimiento y reduce los costos asociados con el procesamiento de grandes volúmenes de datos.
Clustering
El clustering organiza los datos dentro de una tabla según una o más columnas de forma que los registros con valores similares se almacenan cerca unos de otros. Esta técnica es útil para mejorar la eficiencia de las consultas que filtran o agrupan por las columnas seleccionadas para el clustering. Al usar clustering junto con particionamiento, se puede mejorar aún más el rendimiento y reducir los costos de las consultas, ya que BigQuery puede leer menos datos y realizar búsquedas más rápidas sobre grandes conjuntos de datos.
Antipatrones
Aunque el particionamiento y el clustering son poderosas herramientas para optimizar el rendimiento y reducir costos, también existen varios antipatrones que debes evitar en BigQuery. Un antipatrón común es no diseñar el esquema de particionamiento y clustering en función de cómo se realizan las consultas. Por ejemplo, particionar por una columna que no se usa frecuentemente en los filtros de las consultas puede resultar en un uso ineficiente del espacio y aumentar los costos de procesamiento. Otro antipatrón es tener un número excesivo de columnas con clustering, lo que puede llevar a una sobrecarga de administración y a tiempos de consulta más lentos.
Además, un error frecuente es realizar consultas sin un uso adecuado de las funciones de agregación o sin aplicar filtros eficientes, lo que puede provocar que se escaneen grandes volúmenes de datos innecesarios, aumentando los costos. Un antipatrón muy importante es el uso de SELECT *, que es común en algunas consultas pero puede ser extremadamente costoso en BigQuery. Esto se debe a que BigQuery es un sistema de bases de datos columnar, lo que significa que almacena los datos por columnas, no por filas. Al usar SELECT *, estás solicitando todos los datos de todas las columnas, lo que puede resultar en una gran cantidad de datos escaneados innecesariamente, aumentando los costos de la consulta y afectando el rendimiento. En su lugar, se recomienda seleccionar solo las columnas necesarias para la consulta, optimizando tanto el rendimiento como los costos.
Otro antipatrón es la sobrecarga de las consultas con un número elevado de uniones o subconsultas complejas, lo que puede impactar negativamente el rendimiento.
Multirregión en GCS y BigQuery
Google Cloud Storage (GCS) y BigQuery ofrecen configuraciones multirregión que permiten distribuir datos y consultas a través de múltiples ubicaciones geográficas, lo que puede proporcionar ventajas significativas en términos de disponibilidad y desempeño. Sin embargo, es fundamental comprender las ventajas y desventajas que tienen estas configuraciones para tomar decisiones informadas al diseñar arquitecturas.
Google Cloud Storage (GCS)
Ventajas:
- Alta disponibilidad y durabilidad: Los datos se replican automáticamente entre diferentes regiones dentro del continente seleccionado. Esto asegura que, en caso de un fallo en una región específica, el acceso a los datos no se vea afectado.
- Optimización del acceso global: Los usuarios y servicios distribuidos en diferentes partes del mundo pueden acceder a los datos de manera más eficiente, aprovechando la proximidad geográfica.
- Facilidad de gestión: Al elegir una configuración multirregión, no es necesario gestionar manualmente la replicación entre regiones. Google Cloud maneja automáticamente este proceso.
Desventajas:
- Costo más elevado: Al elegir una ubicación multirregión, los costos de almacenamiento pueden aumentar, ya que los datos se replican en varias ubicaciones. Este costo adicional debe ser evaluado en función de los requisitos de disponibilidad.
- Latencia adicional: Si bien el acceso global puede beneficiarse de la proximidad, también se debe considerar que el tráfico interregional puede generar latencias, especialmente si se usan servicios fuera de la región multirregión.
Utiliza ubicaciones multirregión cuando la alta disponibilidad y la resiliencia sean esenciales para tu aplicación. Por ejemplo, aplicaciones críticas que deben estar siempre disponibles, incluso durante desastres regionales.
Si los costos son una preocupación, evalúa si realmente necesitas una configuración multirregión o si una ubicación única o una configuración regional puede ser suficiente para tus necesidades.
BigQuery
Ventajas:
- Desempeño optimizado para consultas globales: Cuando se ejecutan consultas en conjuntos de datos almacenados en una configuración multirregión, BigQuery puede optimizar la distribución de la carga de trabajo, ejecutando partes de las consultas cerca de los datos para reducir la latencia.
- Alta disponibilidad de datos: Al igual que con GCS, los datos almacenados en BigQuery en una ubicación multirregión se replican automáticamente entre varias regiones, garantizando la durabilidad y disponibilidad incluso en situaciones de fallos regionales.
- Reducción de la latencia para usuarios globales: Las consultas pueden ejecutarse más rápidamente si los datos están cerca de la ubicación de los usuarios finales, mejorando el tiempo de respuesta en escenarios globales.
Desventajas:
- Costo por consultas interregionales: Aunque BigQuery maneja el procesamiento de manera eficiente, las consultas que abarcan múltiples regiones pueden generar costos adicionales, ya que se incurre en tarifas de transferencia de datos entre regiones.
- Posible complejidad en la gestión de datos: Al almacenar datos en una configuración multirregión, debes estar al tanto de las políticas de acceso y las implicaciones de rendimiento para asegurarte de que las consultas no se vean innecesariamente afectadas por la latencia interregional.
Si tu aplicación requiere análisis en tiempo real o consultas que involucren grandes volúmenes de datos distribuidos globalmente, usar una configuración multirregión en BigQuery puede mejorar significativamente el rendimiento.
Considera el costo de las transferencias interregionales si tu flujo de trabajo involucra consultas entre datos almacenados en diferentes regiones. Para evitar costos innecesarios, puede ser útil limitar las consultas a una región específica o consolidar los datos en una región centralizada.
Ten en cuenta la ubicación de tus usuarios y servicios, ya que elegir la región correcta puede impactar tanto el costo como el desempeño de las consultas.
Herramientas para monitorear y controlar costos y rendimiento
En el entorno de la nube, controlar los costos y mantener el rendimiento óptimo de los servicios es esencial para una gestión eficiente de los recursos. Google Cloud ofrece varias herramientas que facilitan el monitoreo, la optimización de costos y el análisis del rendimiento de servicios como Google Cloud Storage (GCS) y BigQuery. A continuación, revisamos algunas de las herramientas más útiles disponibles en Google Cloud para gestionar ambos servicios.
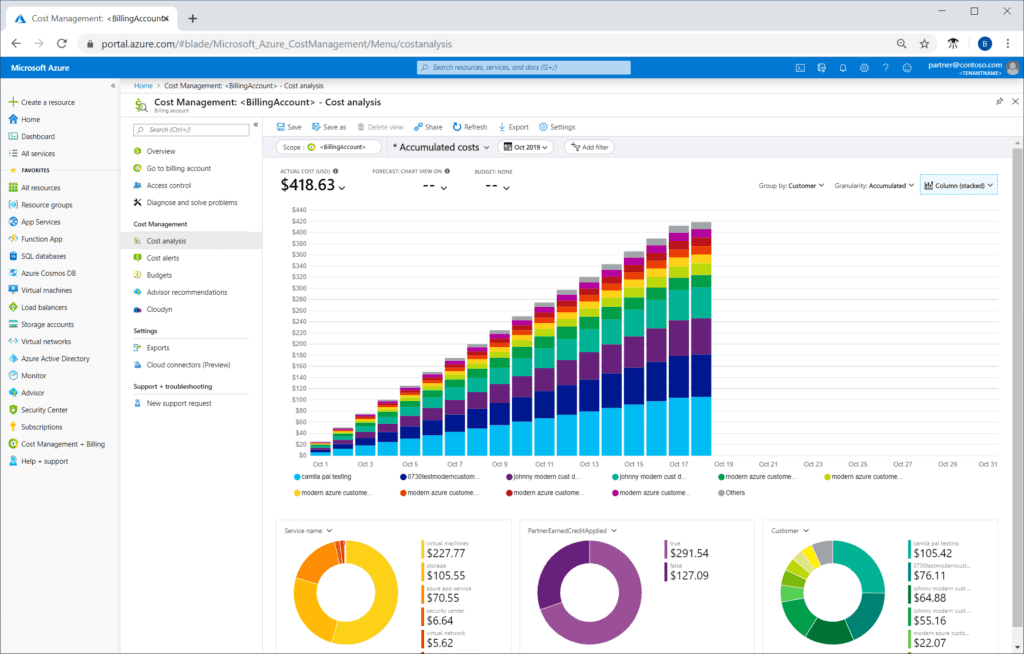
Google Cloud Billing(Monitoreo de Costos y Estimaciones)
Es una de las herramientas principales para gestionar y monitorear los costos asociados con todos los servicios de Google Cloud, incluyendo GCS y BigQuery. Proporciona visibilidad detallada sobre el uso de los servicios y las tarifas que se están generando.
Funcionalidades clave:
- Estadísticas de uso y costos: Permite obtener informes detallados sobre el uso de GCS y BigQuery, segmentados por proyectos, servicios o incluso usuarios. Puedes analizar los costos históricos, estimar los gastos futuros y crear alertas para evitar sorpresas.
- Presupuestos y alertas: Puedes configurar presupuestos para cada servicio o proyecto y recibir alertas si los costos superan ciertos umbrales. Esto es especialmente útil para evitar gastos imprevistos en BigQuery, donde las consultas interregionales o el almacenamiento de grandes volúmenes de datos pueden generar costos adicionales.
- Informes de costos detallados: Accede a informes granulares sobre las tarifas de almacenamiento, transferencia de datos, ejecución de consultas y otros servicios relacionados. Esta información es útil para identificar áreas donde se puede optimizar el uso y reducir costos.
- Cost Breakdown: Puedes segmentar los costos por servicio, región, etiquetas o proyectos. Esto es útil para desglosar específicamente cuánto estás gastando en GCS y BigQuery, permitiéndote identificar áreas donde podrías reducir el gasto.
- Recomendaciones de optimización: Google Cloud Billing ofrece recomendaciones personalizadas para optimizar los costos, por ejemplo, sugiriendo la transición de almacenamiento a clases más económicas en GCS o la revisión de patrones de consultas costosas en BigQuery.
- Forecasting y Análisis Predictivo: La herramienta también ofrece funcionalidades para predecir los costos futuros basándose en el uso histórico y la tendencia actual, lo que te ayuda a planificar los recursos de manera más eficiente.
Usa Google Cloud Billing para establecer un control regular de los costos de GCS y BigQuery, y configura alertas para mantenerte dentro de los límites presupuestarios. Además, puedes crear informes personalizados para realizar un seguimiento más efectivo.
Utiliza las recomendaciones de optimización de Google Cloud Cost Management para ajustar la infraestructura de GCS y BigQuery a tus necesidades reales, asegurando una gestión de costos más eficaz.
Google Cloud Monitoring(Monitoreo de los servicios)
Para gestionar el rendimiento de GCS y BigQuery, Google Cloud Monitoring es la herramienta recomendada. Esta herramienta permite visualizar el estado de los recursos de Google Cloud, incluidas las métricas de rendimiento de almacenamiento y consultas.
Funcionalidades clave:
- Métricas de rendimiento de GCS: Puedes monitorear tanto el tiempo de respuesta como la tasa de transferencia de los objetos almacenados en Google Cloud Storage (GCS), lo que te ayudará a detectar problemas de rendimiento que puedan afectar la eficiencia en el acceso a los datos. Además, es posible monitorear el uso del almacenamiento y obtener una visión clara de la cantidad de espacio que cada bucket está utilizando. Esto es clave para identificar rápidamente qué buckets están generando costos elevados, permitiéndote tomar decisiones informadas sobre la gestión del almacenamiento. También es importante monitorear el uso de la API de GCS, ya que una alta cantidad de solicitudes o un uso ineficiente de la API puede generar costos adicionales y afectar el rendimiento.
- Métricas de rendimiento de BigQuery: Google Cloud Monitoring ofrece métricas detalladas sobre el rendimiento de las consultas en BigQuery, tales como el tiempo de ejecución, la cantidad de datos procesados y los recursos consumidos. Estas métricas son fundamentales para identificar consultas que podrían estar generando cuellos de botella o costos elevados. Además, es posible monitorear el uso de la API de BigQuery, lo que te permitirá detectar patrones anómalos en el consumo de la API, evitando posibles sobrecargos y asegurando un rendimiento óptimo de tus consultas. Monitorear tanto el uso de la API como el almacenamiento te permite optimizar tanto la infraestructura como los costos asociados con el procesamiento de datos.
- Alertas de rendimiento: Al igual que con los costos, puedes establecer alertas para el rendimiento, como el tiempo de respuesta de GCS o la duración de las consultas en BigQuery, para tomar medidas preventivas si los indicadores de rendimiento superan ciertos umbrales.
Usa Google Cloud Monitoring para realizar un seguimiento constante de las métricas clave relacionadas con GCS y BigQuery, asegurando que ambas plataformas funcionen de manera eficiente y sin cuellos de botella que puedan afectar la experiencia del usuario o generar costos innecesarios.
BigQuery Query Plan Explanation(Optimización de Consultas)
Una de las principales preocupaciones en BigQuery es el rendimiento de las consultas. BigQuery Query Plan Explanation es una herramienta avanzada que permite examinar los planes de ejecución de las consultas y entender cómo BigQuery procesa los datos.
Funcionalidades clave:
- Plan de ejecución: Analiza el plan de ejecución de las consultas, lo que te permite identificar posibles optimizaciones, como el uso de índices, particiones o la reorganización de las tablas.
- Recomendaciones de optimización: En el plan de ejecución, BigQuery proporciona recomendaciones sobre cómo mejorar la consulta para reducir los costos y mejorar el tiempo de ejecución, como evitar la lectura de datos innecesarios o mejorar el uso de recursos.
- Optimización de costos: Al mejorar las consultas, puedes reducir significativamente los costos asociados con la ejecución de las mismas, especialmente en escenarios donde se procesan grandes volúmenes de datos.
Utiliza BigQuery Query Plan Explanation para revisar y optimizar las consultas que realizan un uso intensivo de recursos, asegurando que el procesamiento de datos se haga de la manera más eficiente posible.
Preguntas claves
Para poder tomar la mejor decisión te puedes basar en la siguiente serie de preguntas y escenarios planteados:
- ¿Cuál es el volumen de datos que manejarás?
- Escenario 1: Datos a gran escala
Si estás gestionando un sistema de análisis de logs de aplicaciones distribuidas, el volumen de datos podría ser muy alto, con millones de registros generados cada hora. En este caso, podrías optar por usar GCS con la clase de almacenamiento Nearline o Coldline para los logs que no se consultan frecuentemente, pero que deben conservarse por un periodo largo. - Escenario 2: Datos pequeños y estáticos
Si manejas un sitio web con archivos estáticos (por ejemplo, imágenes, CSS, etc.), el volumen de datos puede ser pequeño y relativamente estable. En este caso, podrías almacenar los archivos en un bucket con la clase Standard, ya que el acceso será frecuente y rápido.
- Escenario 1: Datos a gran escala
- ¿Cuál es el ciclo de vida de tus datos?
- Escenario 1: Datos temporales
Imagina que gestionas un sistema de análisis de datos en tiempo real, donde los datos sólo tienen valor durante unas horas o días (por ejemplo, registros de métricas de uso de una aplicación móvil). Después de cierto tiempo, estos datos ya no son útiles. En este caso, puedes configurar un ciclo de vida en GCS para mover los archivos a Coldline después de 30 días y, después de 90 días, eliminarlos. - Escenario 2: Datos históricos y de cumplimiento
Si tienes datos que deben ser almacenados durante años por razones de cumplimiento o auditoría (como registros financieros o médicos), debes asegurarte de que estos se conserven en almacenamiento de largo plazo y estén protegidos. En este caso, Coldline o Archive en GCS serían las mejores opciones, y podrías aplicar políticas de retención para garantizar que los datos se mantengan durante el tiempo requerido.
- Escenario 1: Datos temporales
- ¿Necesitas versionar tus datos?
- Escenario 1: Versionado de datos críticos
Supongamos que estás manejando datos sensibles, como documentos legales o informes financieros, y necesitas poder recuperar versiones anteriores en caso de errores o cambios no deseados. Habilitar el versionado en GCS sería útil, ya que te permite mantener un historial de las versiones de cada archivo. Sin embargo, es importante configurar una política para eliminar versiones antiguas después de un tiempo para evitar el uso excesivo de almacenamiento. - Escenario 2: Datos no modificables
Si trabajas con archivos que no cambian con frecuencia, como archivos multimedia o datos de respaldos que se actualizan solo una vez cada cierto tiempo, el versionado podría no ser necesario. En este caso, puedes evitar habilitar el versionado y ahorrar en costos de almacenamiento innecesarios.
- Escenario 1: Versionado de datos críticos
- ¿Cómo organizar tus datos en GCS?
- Escenario 1: Múltiples tipos de datos y permisos diferenciados
Si trabajas con una organización que maneja diferentes tipos de datos (por ejemplo, datos de clientes, logs de servidores, imágenes de productos, etc.), lo ideal sería crear diferentes buckets para cada tipo de datos. Esto no solo organiza mejor los recursos, sino que también permite aplicar políticas de seguridad y ciclo de vida diferenciadas.- Bucket 1: Logs de servidores (logs)
- Bucket 2: Archivos de usuarios (user-data)
- Bucket 3: Imágenes de productos (product-images)
- Además, puedes aplicar políticas de ciclo de vida distintas en cada bucket. Por ejemplo, los logs de servidores pueden tener una retención corta (mover a Coldline después de 30 días), mientras que las imágenes de productos pueden estar almacenadas a largo plazo en Nearline o Archive.
- Escenario 2: Múltiples proyectos y entornos
En un entorno con varios proyectos, podrías crear un bucket por proyecto o incluso por entorno (producción, desarrollo, pruebas) para mantener el aislamiento y la gestión controlada.
- Escenario 1: Múltiples tipos de datos y permisos diferenciados
- ¿BigQuery será utilizado para análisis en tiempo real o consultas históricas?
- Escenario 1: Análisis en tiempo real
Supón que estás trabajando con un sistema de monitoreo de eventos en tiempo real, donde los datos se generan y se consultan de inmediato (por ejemplo, análisis de comportamiento de usuarios en una plataforma web). En este caso, deberías configurar tablas particionadas en BigQuery por fecha para asegurarte de que las consultas solo analicen los datos más recientes y no incurras en costos innecesarios por escanear grandes volúmenes de datos históricos.
Partición por fecha: Crea tablas particionadas por fecha para consultas diarias de los datos más recientes. - Escenario 2: Consultas históricas
Si trabajas con un sistema donde las consultas se hacen sobre grandes volúmenes de datos históricos (por ejemplo, análisis de tendencias de ventas a lo largo de varios años), entonces deberías usar clustering en BigQuery para organizar los datos y optimizar las consultas por las columnas más consultadas (como ID de producto, categoría, etc.).
Clustering: Crear un clustering por producto_id y categoria_id para optimizar las consultas sobre estos campos.
- Escenario 1: Análisis en tiempo real
- ¿Tienes políticas de seguridad y acceso claras para cada servicio?
- Escenario 1: Acceso diferenciado para equipos
Si tienes diferentes equipos (por ejemplo, equipo de desarrollo, operaciones, y análisis de datos), es fundamental definir roles y permisos para cada bucket en GCS y las tablas en BigQuery. Asegúrate de que solo los usuarios autorizados puedan modificar o acceder a datos sensibles.
GCS: Usa IAM para otorgar permisos específicos a los diferentes buckets. Por ejemplo, solo el equipo de operaciones debe tener acceso de lectura/escritura al bucket de logs (logs).
BigQuery: Asigna permisos de lectura a los analistas de datos para las tablas de BigQuery, pero solo permite escritura al equipo de desarrollo. - Escenario 2: Acceso por ubicación geográfica
Si estás trabajando en una región con regulaciones de protección de datos (por ejemplo, en la UE), puedes configurar ubicaciones regionales en GCS para asegurar que los datos se almacenan en una región específica y controlar el acceso a ellos de acuerdo con las normativas locales.
Con estos escenarios, tienes un marco claro de cómo abordar las decisiones de almacenamiento, ciclo de vida, versionado y seguridad, según las necesidades de tu proyecto.
- Escenario 1: Acceso diferenciado para equipos
Optimización
Para que puedas optimizar los costos aplicando las recomendaciones que se vieron anteriormente, es necesario que conozcas cómo están configurados los servicios, para esto puedes revisar varios ejemplos de código para obtener los metadatos de tus recursos en Google Cloud Storage (GCS) y BigQuery, utilizando las APIs de Google Cloud (en Python). Esto te permitirá obtener información sobre la configuración actual y ayudarte a identificar posibles mejoras o cambios.
- Revisar los metadatos de un bucket en GCS
- Este código obtiene información sobre un bucket en Google Cloud Storage, incluyendo la clase de almacenamiento, las políticas de ciclo de vida, y más.
- Instalar dependencias: Si no lo has hecho aún, instala la biblioteca cliente de Google Cloud Storage en Python:
pip install google-cloud-storage
Código para obtener metadatos del bucket:
import csv
import concurrent.futures
from google.cloud import storage
#cambiar nombre del project-id
client = storage.Client(project="project-id")
def obtener_metadatos_bucket(bucket):
metadatos = {
"nombre_bucket": bucket.name,
"ubicacion_bucket": bucket.location,
"clase_almacenamiento": bucket.storage_class,
"versionamiento_habilitado": bucket.versioning_enabled,
"reglas_ciclo_vida": str(bucket.lifecycle_rules) if bucket.lifecycle_rules else "No hay reglas",
}
objetos = []
blobs = client.list_blobs(bucket.name)
for blob in blobs:
objetos.append({
"nombre_objeto": blob.name,
"tamano_objeto": f"{blob.size} bytes"
})
return metadatos, objetos
def guardar_metadatos_csv(nombre_archivo, metadatos_buckets):
with open(nombre_archivo, mode='w', newline='') as file:
writer = csv.writer(file)
# Encabezados
writer.writerow(["Nombre del Bucket", "Ubicación", "Clase de Almacenamiento", "Versionamiento", "Reglas Ciclo de Vida", "Nombre del Objeto", "Tamaño del Objeto"])
# Escribir los metadatos de cada bucket
for metadatos, objetos in metadatos_buckets:
for objeto in objetos:
writer.writerow([
metadatos["nombre_bucket"],
metadatos["ubicacion_bucket"],
metadatos["clase_almacenamiento"],
metadatos["versionamiento_habilitado"],
metadatos["reglas_ciclo_vida"],
objeto["nombre_objeto"],
objeto["tamano_objeto"]
])
def procesar_bucket(bucket):
try:
metadatos, objetos = obtener_metadatos_bucket(bucket)
return metadatos, objetos
except Exception as e:
print(f"Error al procesar el bucket {bucket.name}: {e}")
return None
def obtener_y_guardar_metadatos():
metadatos_buckets = []
buckets = client.list_buckets()
# Usar ThreadPoolExecutor para paralelizar la carga de metadatos
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = {executor.submit(procesar_bucket, bucket): bucket for bucket in buckets}
for future in concurrent.futures.as_completed(futures):
resultado = future.result()
if resultado:
metadatos_buckets.append(resultado)
guardar_metadatos_csv('metadatos_buckets.csv', metadatos_buckets)
print("Metadatos guardados en el archivo 'metadatos_buckets.csv'")
if __name__ == "__main__":
obtener_y_guardar_metadatos()
Este script te permitirá ver información sobre:
- La ubicación del bucket (para asegurarte de que cumple con las normativas de regulación de datos, si es necesario).
- La clase de almacenamiento (Standard, Nearline, Coldline, Archive).
- Si el versionado está habilitado.
- Las políticas de ciclo de vida configuradas para el bucket.
- Un listado de objetos dentro del bucket y su tamaño.
- Revisar los metadatos de una tabla en BigQuery
Este código obtiene metadatos sobre una tabla de BigQuery, como su esquema, particiones, y detalles de almacenamiento.
Instalar dependencias: Si aún no lo has hecho, instala el SDK de Google Cloud para BigQuery:
pip install google-cloud-bigquery Código para obtener metadatos de una tabla en BigQuery:
import csv
import concurrent.futures
from google.cloud import bigquery
from google.api_core.exceptions import NotFound
#cambiar nombre del project-id
client = bigquery.Client(project="project-id")
def obtener_metadatos_tabla(dataset_id, table_id):
try:
table_ref = client.dataset(dataset_id).table(table_id)
table = client.get_table(table_ref)
partition_field = "N/A"
if table.time_partitioning and table.time_partitioning.field:
partition_field = table.time_partitioning.field
metadatos = {
"dataset_id": dataset_id,
"table_id": table.table_id,
"descripcion": table.description,
"esquema": ', '.join([f"{field.name} ({field.field_type})" for field in table.schema]),
"partitioning_type": table.partitioning_type if table.partitioning_type else "No particionada",
"partition_field": partition_field, # Usamos la variable con la partición
"clustering_fields": ', '.join(table.clustering_fields) if table.clustering_fields else "No clustering",
"tamaño_bytes": table.num_bytes,
"numero_filas": table.num_rows
}
return metadatos
except NotFound:
print(f"Tabla no encontrada: {dataset_id}.{table_id}")
return None
def obtener_tablas_datasets():
metadatos_tablas = []
datasets = client.list_datasets()
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = []
for dataset in datasets:
tablas = client.list_tables(dataset.dataset_id)
for tabla in tablas:
futures.append(executor.submit(obtener_metadatos_tabla, dataset.dataset_id, tabla.table_id))
for future in concurrent.futures.as_completed(futures):
metadatos = future.result()
if metadatos:
metadatos_tablas.append(metadatos)
return metadatos_tablas
def guardar_metadatos_csv(nombre_archivo, metadatos_tablas):
with open(nombre_archivo, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=metadatos_tablas[0].keys())
writer.writeheader()
writer.writerows(metadatos_tablas)
def procesar_metadatos():
metadatos_tablas = obtener_tablas_datasets()
guardar_metadatos_csv('metadatos_tablas.csv', metadatos_tablas)
print("Metadatos guardados en el archivo 'metadatos_tablas.csv'")
if __name__ == "__main__":
procesar_metadatos()
Este script te permitirá obtener información clave sobre:
- El esquema de la tabla (nombres y tipos de los campos).
- Particionamiento: Si la tabla está particionada por fecha u otra columna y cómo se está gestionando.
- Clustering: Si la tabla usa clustering para optimizar las consultas.
- Tamaño de la tabla y el número de filas.
- Obtener detalles sobre el uso de GCS y BigQuery
Para obtener más detalles acerca del uso y las métricas de tus servicios de GCS y BigQuery, puedes utilizar el servicio de Cloud Monitoring o la API de Stackdriver para obtener métricas sobre almacenamiento y consultas, pero esto va más allá de revisar metadatos y entra en el análisis de rendimiento.
Conclusión
En resumen, la optimización de los costos en Google Cloud Platform, especialmente en servicios clave como GCS y BigQuery, es fundamental para mantener un control eficiente sobre el gasto y maximizar el rendimiento de tus recursos. Siguiendo las recomendaciones sobre almacenamiento, ciclo de vida de los datos, versionado y seguridad, podrás tomar decisiones más informadas y alineadas con las necesidades específicas de tu proyecto. Además, con las herramientas y APIs disponibles, puedes auditar y ajustar continuamente tu infraestructura para asegurar que siempre estés aprovechando al máximo cada recurso. Con una gestión adecuada, los costos no tienen por qué ser un obstáculo, sino una oportunidad para mejorar la eficiencia y la escalabilidad de tu plataforma en la nube.
Julián Felipe Parra
Technical Specialist
¿Quieres saber más de lo que ofrecemos y ver otros casos de éxito?
Te puede interesar